Metagenómica
From Wikipedia, the free encyclopedia

La metagenómica se define como el estudio del material genético recuperado directamente de muestras ambientales, sin necesidad de aislar ni cultivar los microorganismos presentes. Este campo ha transformado nuestra comprensión de la biodiversidad microbiana y sus funciones ecológicas en diferentes ambientes.[1]
A diferencia de la microbiología tradicional o de la genómica microbiana clásica, que dependen de la clonación y el cultivo de cepas individuales, la metagenómica analiza de manera directa el ADN total de una comunidad microbiana, permitiendo no solo conocer qué microorganismos están presentes, sino también qué funciones metabólicas y genes poseen.[2]
Con el desarrollo de técnicas de secuenciación masiva (NGS), la metagenómica moderna utiliza tanto la secuenciación de amplicones (por ejemplo, 16S, 18S o ITS) como la secuenciación metagenómica tipo shotgun para recuperar y analizar fragmentos de todos los genes presentes en una muestra ambiental. Estos avances han permitido descubrir nuevos linajes microbianos, reconstruir genomas metagenómicos (MAGs) y explorar las funciones metabólicas de comunidades completas, desde ecosistemas marinos hasta el microbioma humano.[3][1]
Hoy en día, gracias a la continua reducción en los costos de secuenciación y a la disponibilidad de herramientas bioinformáticas más robustas, la metagenómica permite estudiar la ecología microbiana a una escala y resolución sin precedentes. Este enfoque no solo ha revolucionado la biología ambiental y evolutiva, sino que también tiene aplicaciones en biotecnología, salud humana, agricultura sostenible y monitorización ambiental.[4]
El término "metagenómica" fue utilizado por primera vez por, entre otros, Jo Handlesman, Jon Clardly y Robert M. Goodman. Fue en 1998 cuando apareció por primera vez en una publicación científica.[5] El término metagenoma hacía referencia a un abordaje que pretendía analizar una colección de genes secuenciados de una muestra ambiental como si se tratara de un único genoma. Recientemente, Kevin Chen y Lior Pachter (investigadores de la Universidad de California, en Berkeley), definieron la metagenómica como «la aplicación de técnicas genómicas modernas para el estudio directo de comunidades de microorganismos en su entorno natural, evitando la necesidad de aislar y cultivar cada una de las especies que componen la comunidad».[6]
Historia
La secuenciación convencional comienza con un cultivo de células idénticas como fuente de ADN. Sin embargo, los primeros estudios metagenómicos revelaron que hay muchos grupos de microorganismos en diferentes ambientes que no pueden ser cultivados y por lo tanto no pueden ser secuenciados. Estos primeros estudios se concentraban en las secuencias de ARN ribosomal 16S que son relativamente cortas, normalmente conservada dentro de una especie, y generalmente diferente entre especies. Muchas secuencias del ARNr 16S que han sido encontradas no corresponden a ninguna especie cultivada, indicando que hay una gran cantidad de organismos que no han sido aislados. Estos estudios de los genes de ARNr que se toman directamente del medio ambiente revelaron que los métodos de cultivos básicos encuentran menos del 1% de las bacterias y arqueas en una muestra.[7] Gran parte del interés en la metagenómica viene de estos descubrimientos, que demostraron que la gran mayoría de los microorganismos han pasado desapercibidos.
Los primeros trabajos moleculares llevados a cabo en el campo fueron dirigidos por Norman R. Pace y sus colegas, quienes usaron PCR para explorar la diversidad de las secuencias de ARN ribosomal.[8] La percepción que se obtuvo a partir de estos estudios tan avanzados condujeron a Pace a proponer la idea de clonar ADN directamente de muestras del medio ambiente a principios de 1985.[9] Esto condujo al primer reporte de aislamiento y clonación ADN desde muestras ambientales, publicado por Pace y sus colegas en 1991,[10] cuando Pace estaba en el Departamento de Biología en la Universidad de Indiana. Considerables esfuerzos aseguraron que no se tratase de falsos positivos del PCR y apoyaron la existencia de una comunidad compleja e inexplorada de especies. Aunque esta metodología estaba limitada a explorar genes no codificadores para proteínas que se conservan bastante, también ayudó a realizar las primeras observaciones microbianas basadas en la morfología demostrando que la diversidad era mucho más compleja que la conocida por los métodos de cultivo. Poco después de eso Healy reportó el aislamiento metagenómico de genes funcionales de "zoolibraries" construidas a partir de un cultivo complejo de organismos ambientales crecidos en un laboratorio en hierbas secas en 1995.[11] Tras dejar el laboratorio de Pace, Edward DeLong continuó en el campo y ha publicado trabajos que básicamente ha fijado las bases de trabajo para ofilogenias ambientales basado en la firma de secuencias 16S, empezando con la construcción de bibliotecas de muestras marinas por parte de su equipo.[12]
En 2002, Mya Breitbart, Forest Rohwer y sus colegas utilizaron la secuenciación de escopeta (ver abajo) para el ambiente para mostrar que 200 litros de agua de mar contienen más de 5000 virus diferentes.[13] Estudios subsiguientes demostraron que hay más de mil especies virales en las heces humanas y posiblemente un millón de virus diferentes por kilogramo de sedimento marino, incluyendo bacteriófagos. Básicamente todos los virus en estos estudios eran especies nuevas. En 2004, Gene Tyson, Jill Banfield, y sus colegas en University of California, Berkeley y el Joint Genome Institute secuenciaron el ADN extraído de un sistema de drenaje de minas de ácidos[14] Este esfuerzo resultó en los genomas completos o casi completos de un grupo de bacterias y arqueas que habían resistido intentos previos para ser cultivados.[15]
Empezando en el 2003, Craig Venter, líder del proyecto fundado de manera privada y paralelo al Proyecto del Genoma Humano, dirigió la Expedición Global Oceánica de Muestras (GOS), circunnavegando el globo y recolectando muestras metagenómicas durante todo el viaje. Todas estas muestras se secuenciaron usando secuenciación de escopeta, con la esperanza de que fueran identificados nuevos genomas (y por lo tanto nuevos organismos). El proyecto piloto, que se llevó a cabo en el mar de los Sargazos, encontró ADN de casi 2000 especies diferentes, incluyendo 148 tipos de bacterias nunca vistas anteriormente.[17] Venter ha circunnavegado el globo y explorado a fondo la costa Oeste de Estados Unidos, completó una expedición de dos años para explorar el mar Báltico, el mar Mediterráneo y el mar Negro. Los análisis de la información metagenómica recopilada durante dicho viaje revelaron dos grupos de organismos, uno compuesto de taxones adaptado para condiciones ambientales 'feast or famine', y un segundo compuesto de relativamente menos, pero más abundantes y mejor distribuidos taxones, compuestos principalmente de plankton.[18]
En el 2005 Stephan C. Schuster en Penn State University y sus colegas publicaron las primeras secuencias de una muestra ambiental generada mediante secuenciación de alto rendimiento, en este caso pirosecuenciación masiva y paralela desarrollada por 454 Life Sciences.[19] Otro trabajo que apareció a principios de estos estudios fue de Robert Edwards, Forest Rohwer, y sus colegas en el 2006 en San Diego State University.[20]
Secuenciación
La recuperación de secuencias de ADN superiores a unos pocos miles de pares de bases resultaba extremadamente compleja hasta la aparición de técnicas avanzadas de biología molecular que posibilitaron la construcción de bibliotecas genómicas en cromosomas artificiales bacterianos (BACs, Bacterial Artificial Chromosomes). Estos vectores ofrecen una capacidad de inserción significativamente mayor (hasta 300 kb) y una mayor estabilidad en comparación con los vectores plasmídicos o cosmídicos tradicionales, lo que permitió clonar fragmentos extensos de ADN genómico y facilitó los proyectos de secuenciación a gran escala.[21][22]
En el contexto de la metagenómica, la recuperación de fragmentos largos de ADN a partir de muestras ambientales representó un reto durante años, debido a la fragmentación del ADN y la complejidad de las comunidades microbianas. Sin embargo, los avances en las técnicas de clonación y la implementación de BACs, junto con el desarrollo de cromosomas artificiales de levadura (YACs) y cromosomas artificiales humanos (HACs), hicieron posible la manipulación y conservación de secuencias genómicas extensas, incluso de organismos no cultivables.[23]
Posteriormente, la revolución de la secuenciación masiva de nueva generación (NGS) y, más recientemente, las plataformas de tercera generación como PacBio SMRT y Oxford Nanopore Technologies, permitieron obtener lecturas largas (long reads) directamente, reduciendo la dependencia de bibliotecas clonadas y mejorando notablemente la cobertura, continuidad y precisión del ensamblaje genómico.[24] [25] Estas tecnologías han sido clave para la reconstrucción de genomas a partir de metagenomas (MAGs) y la exploración de la diversidad microbiana en ecosistemas naturales y artificiales.
En conjunto, la evolución desde las bibliotecas de BACs hasta las tecnologías de lectura larga ha transformado la genómica y la metagenómica, haciendo posible recuperar y ensamblar fragmentos de ADN que antes resultaban inaccesibles, con aplicaciones que abarcan desde la genómica comparativa hasta la ecología microbiana y la biotecnología ambiental.[26]

Secuenciación de alto rendimiento
La secuenciación de alto rendimiento (High-Throughput Sequencing, HTS), también conocida como secuenciación de nueva generación (Next-Generation Sequencing, NGS), ha revolucionado el estudio de la diversidad microbiana y la metagenómica. Estas tecnologías permiten generar millones de lecturas de ADN de forma simultánea, lo que facilita el análisis exhaustivo del material genético presente en muestras ambientales sin necesidad de cultivar los microorganismos.
Los primeros estudios metagenómicos de este tipo emplearon la plataforma 454 Pyrosequencing, la cual marcó el inicio de la era NGS al ofrecer lecturas más rápidas y económicas que la secuenciación tradicional de Sanger.[27] Posteriormente, surgieron otras plataformas como Ion Torrent, Illumina MiSeq/HiSeq/NextSeq, y Applied Biosystems SOLiD, que introdujeron mejoras en precisión, profundidad de lectura y reducción de costos.[28] [26]
En general, estas tecnologías producen lecturas más cortas que la secuenciación de Sanger (~700–900 pb), pero compensan esta limitación con una enorme capacidad de secuenciación. Por ejemplo, mientras que la pirosecuenciación de 454 generaba entre 200–500 megabases de datos, las plataformas Illumina actuales pueden producir más de un terabase (10¹² bases) en una sola corrida, con lecturas que superan los 300 pb por extremo. Esto ha permitido explorar comunidades microbianas complejas y detectar organismos raros o de baja abundancia con una alta resolución sin precedentes.[29]
Además, las tecnologías más recientes, denominadas de tercera generación, como Pacific Biosciences (PacBio SMRT) y Oxford Nanopore Technologies (ONT), han introducido la posibilidad de obtener lecturas ultralargas (hasta cientos de kilobases) sin necesidad de amplificación, lo que mejora la continuidad de los ensamblajes y la detección de estructuras genómicas complejas. [25][24]
Una de las principales ventajas de la secuenciación de alto rendimiento es que no requiere clonación previa del ADN, eliminando así procesos largos, costosos y propensos a sesgos. Esto permite un acceso más directo al ADN ambiental, reduciendo los pasos experimentales y acelerando la generación de datos genómicos.
Secuenciación shotgun
Dentro de las estrategias de secuenciación de alto rendimiento, la secuenciación shotgun representa un enfoque fundamental. Este método consiste en fragmentar aleatoriamente el ADN total extraído de una muestra ambiental en millones de fragmentos cortos, los cuales se secuencian y posteriormente se ensamblan bioinformáticamente para reconstruir secuencias continuas más largas (contigs) o incluso genomas metagenómicos (MAGs), dependiendo de la complejidad de la muestra y cantidad de datos.[29]
Originalmente, la secuenciación shotgun requería la construcción de bibliotecas de clonación en vectores como los cromosomas artificiales bacterianos (BACs). Sin embargo, con el desarrollo de las plataformas de secuenciación masiva, esta etapa se ha vuelto innecesaria, ya que los sistemas NGS permiten obtener directamente un volumen masivo de secuencias, con mayor cobertura y menor costo. [30]
La metagenómica shotgun proporciona una visión integral de la composición y función de las comunidades microbianas: revela qué organismos están presentes (perfil taxonómico) y qué genes o rutas metabólicas potenciales poseen (perfil funcional). Su carácter no dirigido y aleatorio permite detectar también microorganismos raros o no cultivables, que quedarían fuera del alcance de técnicas basadas en cultivos o en marcadores específicos como el gen 16S rRNA .[30][29]
No obstante, la naturaleza aleatoria de la secuenciación shotgun implica que los organismos más abundantes en la muestra estarán sobrerrepresentados, mientras que las especies raras pueden requerir una mayor profundidad de secuenciación para obtener cobertura suficiente. Por ello, los proyectos metagenómicos suelen equilibrar costos, profundidad y complejidad del ensamblaje mediante el uso combinado de tecnologías de lectura corta y larga, junto con estrategias de coensamblaje y binning metagenómico.[31]
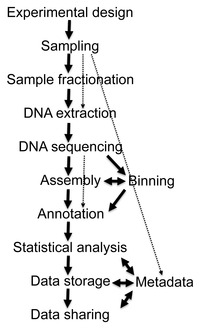
Bioinformática
La cantidad de datos generada por los experimentos de metagenómica es enorme y, además, intrínsecamente ruidosa, ya que contiene fragmentos de ADN procedentes de miles de organismos distintos que coexisten en una misma muestra. En un solo análisis metagenómico pueden detectarse secuencias correspondientes a más de 10000 especies microbianas, muchas de ellas aún no descritas.[32][33] Por ejemplo, en el caso de la microbiota ruminal, un estudio de gran escala recopiló un total de 4941 MAGs a partir de aproximadamente 6,5 terabases de datos generados mediante la combinación de secuenciación de lecturas largas y cortas,[34] lo que permitió ampliar considerablemente el conocimiento sobre la diversidad microbiana del rumen bovino. De manera similar, en el ámbito del microbioma intestinal humano, el catálogo Unified Human Gastrointestinal Genome (UHGG) consolidó 204938 genomas no redundantes pertenecientes a 4644 especies bacterianas,[35] proporcionando un marco de referencia unificado para el estudio de la diversidad y función microbiana en el intestino humano.
El procesamiento de estos volúmenes de datos implica numerosos desafíos bioinformáticos. Las etapas incluyen la limpieza y control de calidad de las secuencias, el ensamblaje de fragmentos en contigs, la agrupación de secuencias en genomas metagenómicos (MAGs), la anotación funcional y taxonómica, y el análisis comparativo entre muestras o ecosistemas.[36][37] Cada una de estas fases requiere herramientas computacionales especializadas y una gran capacidad de cómputo. Por ello, la bioinformática se ha convertido en una disciplina esencial dentro de la metagenómica, permitiendo transformar datos fragmentados y masivos en conocimiento biológico útil sobre la composición, función y ecología de las comunidades microbianas.
Control de calidad de secuencias
El primer paso del análisis de datos metagenómicos consiste en realizar un control de calidad y prefiltrado de las lecturas crudas obtenidas por secuenciación. Este proceso busca eliminar errores técnicos y fuentes de contaminación que podrían sesgar los análisis posteriores. Entre las tareas más comunes se incluyen la filtración por calidad de bases, la eliminación de adaptadores, la remoción de lecturas redundantes o demasiado cortas, y la detección de secuencias contaminantes.[36][38]
Las lecturas con valores de calidad (Q-score) bajos o con presencia de bases ambiguas suelen ser descartadas o recortadas en sus extremos para mejorar la precisión del ensamblaje. Herramientas ampliamente utilizadas para esta etapa incluyen FastQC,[39] que genera reportes visuales de la calidad de las lecturas, y fastp,[40] un programa rápido y automatizado que combina filtrado, recorte, corrección de bases y generación de estadísticas resumidas. Otros programas con funciones similares son Trimmomatic[41] y Cutadapt,[42] que permiten ajustar umbrales de calidad y longitud de manera flexible.
En muestras metagenómicas de origen humano u otros animales, un paso adicional esencial es la remoción de secuencias del hospedero para evitar la presencia de ADN eucariótico en los análisis microbianos. Esto se realiza mediante la alineación de las lecturas contra el genoma de referencia del hospedero y la posterior eliminación de las coincidencias.[36] Herramientas modernas como Hostile[43] automatizan este proceso, ofreciendo una detección rápida y eficiente de secuencias de hospedero; mientras que métodos previos, como DeconSeq[44] y Eu-Detect,[45] también se utilizan con objetivos similares.
La aplicación rigurosa de estos pasos de control de calidad garantiza que los datos finales utilizados para el ensamblaje y la anotación reflejen con mayor fidelidad la composición microbiana real de la muestra, reduciendo el ruido técnico y las posibles contaminaciones.
Ensamblaje
La información derivada de proyectos genómicos y metagenómicos se basa en secuencias de ADN, pero existen diferencias fundamentales entre ambas. En los proyectos genómicos, las secuencias provienen de un solo organismo y suelen presentar una cobertura alta y redundante, lo que facilita un ensamblaje completo y confiable del genoma. En cambio, los proyectos metagenómicos analizan mezclas de ADN de múltiples organismos en una muestra ambiental, por lo que las secuencias obtenidas tienden a ser más fragmentadas, heterogéneas y con menor redundancia.[46]
Actualmente, las lecturas cortas generadas por tecnologías como Illumina son altamente confiables y precisas, con tasas de error muy bajas (generalmente menores al 0.1%). Sin embargo, la dificultad de ensamblar metagenomas no proviene principalmente de los errores de secuenciación, sino de factores biológicos y estructurales intrínsecos a las muestras ambientales. Entre estos factores se incluyen la gran diversidad de especies con abundancias desiguales, la presencia de regiones repetitivas o altamente conservadas entre organismos, y la similitud genética entre cepas cercanas, que puede conducir a contigs quiméricos o ensamblajes ambiguos.[47][46][48]
Existen diversos programas de ensamblaje que utilizan la información de lecturas pareadas (paired-end reads) para mejorar la precisión y continuidad de los ensamblajes. Los primeros ensambladores, como Phrap o Celera Assembler, fueron diseñados para genomas aislados y lecturas largas de Sanger, pero sentaron las bases para los métodos actuales y aún pueden producir resultados aceptables en conjuntos metagenómicos simples. Con la llegada de las tecnologías de segunda generación (por ejemplo, Illumina), que generan grandes volúmenes de lecturas cortas, surgieron ensambladores optimizados basados en grafos de De Bruijn, como Velvet, SOAPdenovo, SPAdes y MEGAHIT. Estos programas están diseñados para manejar la redundancia y el enorme tamaño de los datos metagenómicos, logrando ensamblajes más eficientes y escalables.[47][46][49]
El uso de genomas de referencia puede mejorar la reconstrucción de las especies más abundantes o bien caracterizadas, mediante enfoques de ensamblaje guiado (reference-guided) o híbrido. Sin embargo, este método sigue limitado por la disponibilidad de genomas representativos, que solo abarcan una fracción reducida de la diversidad microbiana conocida.[46]
Binning
Una vez obtenido el ensamblaje, surge un desafío adicional: el binning, que consiste en determinar a qué organismos pertenecen las secuencias ensambladas. Este proceso se apoya en características como la composición del ADN (por ejemplo, contenido GC o frecuencias de k-mers), la cobertura de lectura y la coocurrencia entre muestras, y se implementa en herramientas modernas como MetaBAT2, MaxBin2, CONCOCT o enfoques más recientes basados en aprendizaje automático.[49]
Predicción de genes
Los análisis metagénomicos de las fuentes de información utilixan dos acercamientos en la anotación de regiones codificantes en los cóntigos ensamblados.[48] El primer acercamiento es identificar los genes basándose en la homología con genes que ya estén públicamente disponibles en las bases de datos de secuencia, normalmente por simples búsquedas BLAST. Este tipo de acercamiento está implementado en el programa MEGAN4.[50] El segundo, ab initio, utiliza características intrínsecas de la secuencia para predecir las regiones codificantes basándose en conjuntos de genes de organismos relacionados. Este es el acercamiento tomado por programas comoGeneMark[51] y GLIMMER. La ventaja principal de la predicción ab initio es que permite la detección de regiones codificantes que no tengan homólogos en las bases de datos de secuencias, pero resulta más preciso cuando hay grandes regiones continuas de ADN genómico para comparación.[52]
Diversidad de especies
La anotación de genes proporciona el "que", mientras que las mediciones de la diversidad de especies proporcionan el "quien" .[53] Para poder conectar la función y la composición de la comunidad en metagenomas, las secuencias deben estar agrupadas. El agrupamiento es el proceso de asociar una secuencia en partículas con un organismo.[48] En métodos de agrupamiento por similitud como BLAST se usan para buscar rápidamente marcadores filogenéticos o de otro modo secuencias similares en las bases de datos públicas existentes. Este acercamiento es implementado en MEGAN.[54] Otra herramienta, PhymmBL, utiliza modelos interpolados de Markov para asignar lecturas.[52] MetaPhlAn y AMPHORA son métodos basados en marcadores de clados específicos para estimar la abundancia relativa con desempeños computacionales mejorados.[55] Una vez que las secuencias son agrupadas, es posible llevar a cambo análisis comparativos de la diversidad y la riqueza utilizando herramientas como Unifrac.[52]
Integración de la información
La cantidad masiva de información se secuenciación que no deja de crecer exponencialmente es un reto desalentador que se complica por la complejidad de la metadata asociada con proyectos metagenómicos. La Metadata incluye información detallada acerca de la geografía tridimensional y las características ambientales de la muestra, información física acerca del sitio de la muestra y la metodología del muestreo.[56] Dicha información es necesaria tanto para asegurar la replicabilidad como para permitir el análisis downstream.[57]
Se han desarrollado varias herramientas para integrar la metadata y la información de secuencias, permitiendo un análisis comparativo downstream de diferentes conjuntos de información mediante un número de índices ecológicos. En 2007, Folker Meyer y Robert Edwards y un equipo en Argonne National Laboratory en University of Chicago liberó el Metagenomics Rapid Annotation usando el servidor de Subsystem Technology (MG-RAST), un recurso comunitario para los análisis de conjuntos de metgagenomas.[58] Desde junio del 2012, han sido analizadas más de 14.8 terabases (14x1012 bases) de ADN, con más de 10,000 conjuntos de información pública disponible dentro de MG-RAST. Más de 8,000 usuarios han presentado un total de 50,000 metagenomas a MG-RAST. El sistema Integrated Microbial Genomes/Metagenomes (IMG/M) también proporciona una serie de herramientas para el análisis funcional de comunidades microbianas basado en su secuencia de metagenoma, basado en aislamiento de genomas como referencia incluida del sistema Integrated Microbial Genomes (IMG) y del proyecto Genomic Encyclopedia of Bacteria and Archaea (GEBA).[59]
Una de las primeras y en aquel entonces única herramienta para analizar un metagenoma por alto rendimiento de información obtenida de escopeta fue MEGAN (MEta Genome ANalyzer).[50][54] Una primera versión del programa fue usada en 2005 para analizar el contexto metagenómicos de secuencias de ADN obtenidas de un hueso de mamut.[19] Basado en una comparación en BLAST contra una base de datos de referencia, esta herramienta llevó a cabo tanto el reagrupamiento taxonómico como el funcional, al colocar las lecturas en los nodos de la taxonomía NCBI usando un simple algoritmo de ancestro menos común o en los nodos de SEED o KEGG.[60]
Metagenómica comparativa
Los análisis comparativos entre metagenomas pueden proporcionar una percepción adicional hacia la función de comunidades microbianas complejas y su papel en la salud del huésped.[61] Una comparación múltiple entre metagenomas puede hacerse a un nivel de la composición de la secuencia (comparando contenido GC o tamaño del genoma) taxonomía, diversidad o complemento funcional. Las comparaciones de las estructuras poblacionales y la diversidad filogenética pueden hacerse en la base de 16S y otros marcadores filogenéticos, o —en el caso de comunidades poco diversas— por reconstrucción de genoma del conjunto de información metagenómica.[62] Las comparaciones funcionales entre metagenomas pueden hacerse al comparar secuencias contra las referencias en las bases de datos como COG o KEGG, y tabulando la abundancia por categoría y evaluando cualquier diferencia por significación estadística.[60] Este acercamiento centrado en genes enfatiza el complemento funcional de la comunidad como uno, y no como grupos taxonómicos y demuestra que los complementos funcionales son análogos bajo condiciones ambientales similares.[62] Por consiguiente, la metadata en un contexto ambiental de las muestras metagenómicas es especialmente importante en análisis comparativos, ya que proporciona a los investigadores la habilidad de estudiar el efecto del hábitat sobre la estructura de la comunidad y la función.[52]
Además, varios estudios también han utilizado patrones de uso de oligonucleótidos para identificar las diferencias a través de diversas comunidades microbianas. Ejemplos de dichas metodologías incluyen el acercamiento de Willnet et al, la abundancia relativa del dinucleótido.[63] y el acercamiento de HabiSign por Ghosh et al.[64] Ghosh et al. (2011)[64] también indicó que diferencias en los patrones de uso pueden ser usadas para identificar genes (o lecturas metagenómicas) originándose en hábitats específicos. Además algunos métodos como TriageTools[65] o Compareads[66] detectan lecturas similares entre dos conjuntos de lecturas. La medida de similitud que aplican en las lecturas se basa en el número de palabras idénticas de longitud k compartido por pares de las lecturas.
Un objetivo clave en la metagenómica comparativa es poder identificar grupos microbianos que son responsables de otorgar características específicas a cierto ecosistema. Sin embargo, debido a problemas con las tecnologías de secuenciación de los artefactos deben considerarse como si fuera metagenomeSeq.[67] Otros han caracterizado interacciones inter-microbianas entre los grupos microbianos residentes.. Una aplicación de análisis comparativo metagenómicos basado en GUI llamada Community-Analyzer ha sido desarrollada por Kuntal et al.[68], que implementa una gráfica basada en una correlación y despliega un algoritmo que no solo facilita una visualización rápida de las diferencias en las comunidades microbianas analizadas (en términos de composición taxonómica), pero también proporciona una visión hacia las interacciones inherentes inter-microbianas que ocurren ahí. Notablemente, este algoritmo desplegado también permite la agrupación de los metagenomas basándose en los patrones inter-microbianos probables más que por simplemente comparar valores de abundancias de varios grupos taxonómicos. Además, la herramienta implementa diversas funcionalidades interactivas basadas en GUI que permiten a los usuarios realizar un análisis comparativo estándar a través de microbiomas..
Análisis de datos
Metabolismo de la comunidad
En muchas comunidades bacterianas, naturales o diseñadas (como biorreactores), hay una división significativa de trabajo en el metabolismo (sintropía), durante la cual los desechos de algunos organismos son metabolitos de otros.[69] En dicho sistema, la estabilidad funcional del biorreactor metanogénico requiere la presencia de varias especies sintrópicas. (Syntrophobacterales y Synergistia) trabajando juntas para poder convertir recursos crudos en residuos metabolizados completamente (metano).[70] Usando estudios de comparación de genes y experimento de expresión con microarreglos o investigadores de proteómica pueden crear una red metabólica que vaya más allá de las fronteras de las especies. Dicho estudio requiere un conocimiento detallado acerca de qué versiones de qué proteínas son codificadas por qué especies e, incluso, por qué tipos de qué especies. Por lo tanto, la información de la genómica de comunidad es otra herramienta fundamental (junto con la metabolómica y la proteómica) en la búsqueda para determinar cómo los metabolitos son transferidos y transformados por una comunidad.[71]
Metatranscriptómica
La metagenómica permite a los investigadores acceder la diversidad funcional y metabólica de comunidades microbianas, pero no puede demostrar cual de estos procesos está activo.[62] La extracción y los análisis del ARNm metagenómico (el metatranscriptoma) proporciona información sobre la regulación y perfiles de expresión de comunidades complejas. Debido a las dificultades técnicas (la corta vida media del ARNm, por ejemplo) presentes en la recolección de ARN ambiental, ha habido relativamente pocos estudios metatranscriptómicos in situ de las comunidades microbianas hasta la fecha.[62] Mientras que originalmente estaban limitados a la tecnología de microarreglos, los estudios metatranscriptómicos han usado directamente secuenciación de alto rendimiento del ADNc para proporcionar la expresión del genoma completa y cuantificación de una comunidad microbiana,[62] primero empleada por Leininger et al. (2006) en su análisis de oxidación de amoniaco en suelos.[72]
Virus
La secuenciación metagenómica resulta particularmente útil en el estudio de comunidades virales. Como los virus no tienen un marcador filogenético universal que compartan (como el ARN 16S para bacterias y arquea y el ARN 18S para eucariota), la única manera de acceder a la diversidad genética de la comunidad viral desde una muestra ambiental es a través de la metagenómica. La metagenómica viral debe poder proporcionar más y más información acerca de la diversidad viral y la evolución.[73] Por ejemplo, una fuente de información metagenómica llamada Giant Virus Finder aportó la primera evidencia de la existencia de virus gigantes en un desierto salino.[74]
Aplicaciones
La metagenómica tiene el potencial de avanzar el conocimiento en una gran variedad de campos. También puede aplicarse a la resolución de retos prácticos en medicina, ingeniería, agricultura, sostenibilidad y ecología.[56]
Medicina
Las comunidades microbianas juegan un papel clave en la preservación de la salud humana, pero su composición y el mecanismo por el que hacen esto sigue siendo un misterio.[75] La secuenciación metagenómica está siendo usada para caracterizar las comunidades microbianas de 15-18 sitios del cuerpo de por lo menos 250 individuos. Esto es parte de la Iniciativa del Microbioma Humano, con los objetivos principales de determinar si existe un microbioma humano central, entender los cambios en el microbioma humano que pueden correlacionarse con la salud humana y desarrollar nuevas herramientas tecnológicas y de bioinformática para poder alcanzar dichos objetivos.[76]
Otro estudio médico parte del proyecto MetaHit (Metagenómica de Tracto Intestinal Humano) consistió de 124 individuos de Dinamarca y España saludables, con sobrepeso y pacientes con síndrome del intestino irritable. El estudio intentó categorizar la profundidad y la diversidad filogenética de las bacterias gastrointestinales. Utilizando datos de secuenciación de Illumina GA y SOAPdenovo, de Bruijn, una herramienta basada en gráficas diseñada específicamente para ensamblar lecturas cortas, fueron capaces de generar 6.59 millones de cóntigos mayores a 500 pares de bases para un cóntigo de longitud total de 10.3 Gb y un N50 de 2.2 kb.
El estudio demostró que dos divisiones bacterianas, Bacteroidetes y Firmicutes, constituyen más del 90% de las categorías filogenéticas que dominan la bacteria intestinal. Usando las frecuencias relativas de los genes encontrados dentro del intestino, estos investigadores encontraron 1,244 agrupaciones metagenómicas que son críticamente importantes para la salud del tracto intestinal. Hay dos tipos de funciones en estas agrupaciones: gestión interna y las que son específicas para el intestino. Las agrupaciones de genes de gestión interna son necesarias en todas las bacterias y normalmente son componentes clave en los principales mecanismos metabólicos incluyendo el metabolismo central del carbono y la síntesis de aminoácidos. Las funciones específicas del intestino incluyen adhesión a proteínas huéspedes y la cosecha de azúcares a partir de los glicolípidos globoseries. Pacientes con el síndrome del intestino irritable exhibieron un 25% menos de genes y menor diversidad bacteriana que los individuos que no sufrían de la enfermedad, indicando que cambios en la diversidad de la bioma intestinal del paciente pueden estar asociados con esta condición.
Mientras estos estudio destacan algunas aplicaciones potenciales médicas importantes, solo 31-48.8% de las lecturas puede alinearse a 194 genomas públicos del intestino humano y 7.6-21.2% a los genomas de las bacterias disponibles en GenBank, lo cual indica que hace falta mucha más investigación para capturar los genomas bacterianos necesarios.[77]
Biocombustibles

Los biocombustibles son combustibles derivados de la conversión de biomasa, como en la conversión de celulosa contenida en tallos de maíz y otra biomasa en etanol celulósico.[56] Este proceso depende de los consorcios microbianos que transforman la celulosa en azúcares, seguido de la fermentación de los azúcares para formar etanol. Los microbios ambientan producen una variedad de fuentes de bioenergía incluyendo metano e hidrógeno.[56]
La deconstrucción eficiente a escala industrial de biomasa requiere enzimas nuevas con mayor productividad y menor costo.[78] Los acercamientos metagenómicos al análisis de comunidades microbianas complejas permite la proyección de enzimas con aplicaciones industriales para la producción de biocombustibles como las hidrolasas glicosídicas.[79] Además se requiere conocimiento de como la función de estas comunidades microbianas se requiere para controlarlas y la metagenómica es la herramienta clave para entenderlas. Los acercamientos metagenómicos permiten análisis comparativos entre sistemas microbianos convergentes como fermentadores de biogás[80] o insectos herbívoros como el hongo del jardín de las hormigas cortahojas.[81]
Remediación Ambiental
La metagenómica puede mejorar las estrategias para monitorear el impacto de contaminantes en los ecosistemas y para limpiar los ambientes contaminados, un mejor entendimiento de como las comunidades microbianas se enfrentan con los contaminantes mejora las evaluaciones de los sitios potencialmente contaminados para recuperarlos e incrementar las oportunidades de los ensayo de bioaumentación y bioestimulación funcionen.[82]
Biotecnología
Las comunidades microbianas producen un arreglo de químicos biológicos activos que son usados en competencia y comunicación.[83] Muchos de los fármacos usados hoy en día fueron originalmente descubiertos en microbios; el progresos reciente explotando los ricos recursos genéticos de microbios no cultivables ha dirigido al descubrimiento de nuevos genes, enzimas y productos naturales.[62][84] La aplicación de la metagenómica ha permitido el desarrollo de productos, químicos finos y farmacéuticos donde el beneficio de la síntesis quiral de enzima catalizada es ampliamente reconocido.[85]
Dos tipos de análisis son usados en la bioprospección de la información metagenómica: la proyección impulsada por una función para una característica expresada y proyección impulsada en una secuencia para secuencias de ADN de interés.[86] Los análisis impulsados en una función buscan identificar clones expresando una característica deseada o una actividad útil, seguido por caracterización bioquímica y análisis de secuencia. Este acercamiento está limitado por la disponibilidad de una pantalla adecuada y el requisito de que la característica deseada debe estar expresada en la célula huésped. Además, el bajo rango de descubrimiento (menos de uno por cada 1,000 clones proyectados) y la intensa carga de trabajo que requiere limitan el acercamiento.[87] En contraste, los análisis impulsados por secuencia usan secuencias conservativas de ADN para diseñar los primers para PCR para proyectar clones para la secuencia de interés.[86] En comparación a los acercamientos basados en clonación, usar un acercamiento solo basado en la secuencia reduce la cantidad de exhibición requerida. La aplicación de secuenciación masiva paralela también aumenta de manera importante la cantidad de información de secuenciación generado, la cual requiere fuentes de análisis bioinformático de alto rendimiento.[87] El acercamiento impulsado por secuencia para proyectar está limitado por la amplitud y la precisión de las funciones de los genes presentes en bases de datos de secuencias públicas. En la práctica, en los experimentos se hace uso de una combinación de ambos acercamiento basados en la función de interés, la complejidad de la muestra a proyectarse y otros factores.[87][88]
Agricultura
Los suelos donde crecen las plantas están habitados por comunidades microbianas con un gramo de suelo conteniendo alrededor de 109-1010 células microbianas que comprenden cerca de una gigabase de información de secuencia.[89][90] Las comunidades microbianas que habitan suelos son de las más complejas conocidas por la ciencia, y permanecen poco entendidas a pesar de su importancia económica.[91] Los consorcios microbianos realizan una variedad de servicios ecológicos necesarios para el crecimiento de plantas, incluyendo fijar el nitrógeno de la atmósfera, el ciclo de nutrientes, supresión de enfermedades y secuestro de hierro y otro metales.[83] Las estrategias funcionales metagenómicas están siendo usadas en explorar la interacción entre plantas y microbios a través del cultivo independiente de las comunidades microbianas.[92] Al permitir una percepción de los papeles de miembros de la comunidad no cultivados en el ciclo de los nutrientes y la promoción del crecimiento de las plantas, los acercamientos metagenómicos puede contribuir a una mejor detección de enfermedades en cosechas y ganado y la adaptación de mejores prácticas agrícolas que mejoren la salud de las cosechas al aprovechar la relación entre los microbios y las plantas.[56]
Ecología
La metagenómica puede proporcionar una percepción muy importante hacia la ecología funcional las comunidades ambientales.[93] Los análisis metagenómicos del consorcio de bacterias encontrados en la defecación de los leones marinos australianos sugiere que las heces ricas en nutrientes de los leones marinos pueden ser un nutriente importante para ecosistemas costeros. Esto es porque las bacterias que son expulsadas simultáneamente con las heces son ideales para descomponer los nutrientes en las heces en una forma biodisponible que puede ser tomada en la cadena alimenticia.[94]
La secuenciación del ADN también puede ser usada de manera más amplia para identificar especies presentes en un cuerpo de agua,[95] los escombros filtrados del aire o una muestra de tierra. Esto puede establecer el rango de especies invasoras y especies en peligro al igual que rastrear poblaciones de temporada.