Dominance stochastique
From Wikipedia, the free encyclopedia
La dominance stochastique est un concept utilisé en sciences sociales et développé principalement à partir de la fin des années 1960. C'est une forme d'ordre stochastique (en), qui permet d'établir un classement de différentes propositions dans un ensemble partiellement ordonné.
La dominance stochastique est notamment utilisée en statistiques et dans la théorie des probabilités pour classer les décisions possibles qu’un acteur peut prendre.
La dominance stochastique globale du premier ordre stipule qu'une distribution est préférée à une autre si et seulement si la fonction de répartition de la distribution préférée n'est jamais supérieure et au moins une fois strictement inférieure à celle de l'autre distribution[1],[2].
Une dominance stochastique est dite « d'ordre 1 » si, quelle que soit la valeur de la variable, l'une des fonctions ou distributions est systématiquement préférée à l'autre. Si un croisement des courbes s'opère et que, à partir d'une certaine valeur du paramètre qui est testé, la préférence s'inverse, on parle d'une dominance stochastique « d'ordre 2 »[3].
- Dominances stochastiques d'ordres 1 et 2
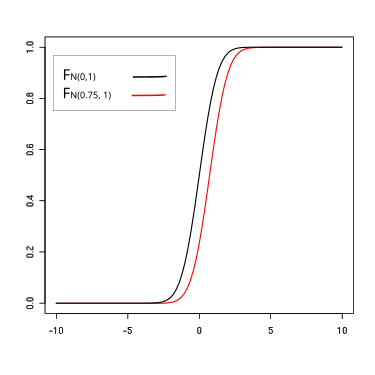 Exemple d'une dominance stochastique d'ordre 1.
Exemple d'une dominance stochastique d'ordre 1.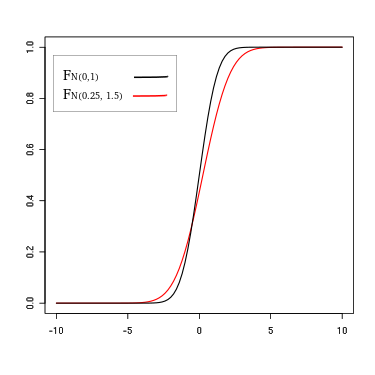 Exemple d'une dominance stochastique d'ordre 2.
Exemple d'une dominance stochastique d'ordre 2.


Historique du concept
La première évocation du concept de dominance stochastique est proposée par Frank Wilcoxon en 1945, puis, deux ans plus tard, dans un article de Henry B. Mann et Donald R. Whitney dans la revue The Annals of Mathematical Statistics en 1947[3].
En économie, le concept est popularisé par Michael Rothschild (en) et Joseph E. Stiglitz dans l'article Increasing risk: I. A definition par en 1970[4].